Top Prompt Evaluation Frameworks in 2025: Helicone, OpenAI Eval, and More
As an AI engineer, you know the drill: your LLM application works flawlessly in testing, but in production, your carefully crafted prompts start producing inconsistent outputs. Despite LLMs' powerful capabilities, their reliability hinges on one critical factor: how we evaluate and optimize our prompts.

Today, building robust evaluations is no longer optional – it's essential for maintaining production reliability. Without evals, it can be very difficult and time intensive to understand how different model or prompt changes affect your output.
In this guide, we will compare the leading prompt evaluation frameworks available today. We will cover:
- Why evaluate your prompts?
- Key metrics for evaluating your prompt
- Top prompt evaluation frameworks in 2025
- How to choose the right framework
| Framework | Pricing Model |
|---|---|
| 1. Helicone | Freemium, Open-source |
| 2. OpenAI Eval | Freemium, Open-source |
| 3. Promptfoo | Freemium, Open-source |
| 4. Comet Opik | Freemium, Open-source |
| 5. PromptLayer | Freemium |
| 6. Traceloop | Freemium, Open-source |
| 7. Braintrust | Freemium |
Let's dive in!
Why evaluate your prompts?
Developers need to test, refine, and benchmark prompts to achieve desired AI outputs. Prompt evaluation frameworks help developers sysytematically do this. Unreliable outputs are caused by:
-
Ineffective prompt engineering. Crafting effective prompts often requires trial and error. You need to use prompt engineering techniques to guide the model towards the desired response. This is quite a manual process and is not a guarantee of consistent results, unless you test it regularly.
-
Unpredictable LLM outputs. LLMs can hallucinate and generate incorrect responses, even with good prompts. Changes to models, parameters, or prompts can significantly impact outputs, requiring active monitoring.
-
Issue with output formatting. Sometimes, LLMs fail to return outputs in the desired format (e.g. JSON, code), breaking agentic workflows that depend on structured responses.
-
Managing long-form content. LLMs often lose coherence in long outputs near token limits. Developers use chunking techniques and prompt evaluation frameworks to preserve quality and context.
-
Lack of specialized tools for prompt testing. There is a growing need for dedicated tools to test, refine, and manage prompts. Such tools would streamline prompt evaluation, improving output quality and reducing iteration time.
Key metrics for evaluating prompt effectiveness
When evaluating prompts for Large Language Models, developers usually focus on the following key metrics:
| Metric | What it measures |
|---|---|
| Output Accuracy | The correctness of the model's response relative to the desired answer |
| Relevance | How pertinent the output is to the given prompt |
| Coherence | The logical consistency and clarity of the response |
| Format Adherence | Whether the output follows the specified format (i.e. JSON or code syntax) |
| Latency | The time taken for the model to generate a response |
| Cost Efficiency | The computational resources required for prompt execution |
Top Prompt Evaluation Frameworks in 2025
| Feature | Helicone | Promptfoo | Comet Opik | PromptLayer | Traceloop | OpenAI Evals | Braintrust |
|---|---|---|---|---|---|---|---|
| Open-Source | ✅ | ✔ | ✔ | - | ✔ | ✔ | - |
| Self-Hosting | ✅ | ✔ | ✔ | ✔ | - | - | ✔ |
| Production-Monitoring Dashboard | ✅ | ✔ | ✔ | ✔ | ✔ | - | - |
| Prompt Versioning | ✅ | - | ✔ | ✔ | ✔ | - | ✔ |
| Prompt Experiments | ✅ | - | ✔ | ✔ | - | - | ✔ |
| Evaluation Templates | ✅ | - | - | ✔ | - | ✔ | ✔ |
| Custom LLM Evaluations | ✅ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
| Dataset Generation | ✅ | ✔ | ✔ | ✔ | ✔ | - | ✔ |
| User Feedback Collection | ✅ | - | Partial (Annotation) | ✔ | ✔ | - | ✔ |
| Traces/Sessions | ✅ | - | ✔ | ✔ | - | - | ✔ |
1. Helicone: Comprehensive Prompt Evaluation Platform
Pricing: Freemium, open-source

What is Helicone?
Helicone is an open-source comprehensive platform for monitoring LLM usage, prompt versioning, experimentation, and evaluation. Its flexibility and user-friendly interface make it a popular choice for developers looking for a comprehensive solution to improve their LLM applications.
Key Features of Helicone
- Prompt Experiments: Test your prompt changes against production data to find what works best. Developers also use Experiments to prevent prompt regressions before deploying to production.
- Evaluators & Scores: Evaluate your prompt outputs using LLM-as-a-judge or custom Python/TypeScript evaluators to quantify output quality.
- Automatic Prompt Tracking: Helicone automatically tracks and versions your prompt changes in code so you can easily roll back to previous versions.
- Sessions: Visualize and debug workflows with multiple prompts, so you can easily drill down and understand exactly where the error occurred.
- User Feedback: Capture user feedback (positive/negative) to measure and refine your prompt.
Differentiators
- Effortless integration: A simple one-line code change to integrate with any provider in seconds.
- Real-time insights: Monitor API usage, costs, and performance in real-time, helping you catch issues before users do.
- Focus on developer experience: Provides optimization features such as custom evaluators, templates, caching, and random sampling of production data.
Don't take our word for it
Nishant Shukla, Director of AI at QA Wolf says: 'the ability to test prompt variations on production traffic without touching a line of code is magical. It feels like we're cheating; it's just that good!'
Basic Setup
Helicone is very flexible and works with any LLM provider. Here's how to set up Helicone with OpenAI to evaluate prompts:
-
Change your baseURL to use Helicone
import OpenAI from "openai"; const openai = new OpenAI({ apiKey: OPENAI_API_KEY, // change the baseURL to use Helicone baseURL: `https://oai.helicone.ai/v1/${HELICONE_API_KEY}/`, }); -
Import Helicone prompts
In your TypeScript/JavaScript code, import the necessary functions:
import { hpf, hpstatic } from "@helicone/prompts"; -
Optional: Create a template and input variables
Use
hpffor dynamic prompts and hpstatic for static prompts.const staticPrompt = hpstatic`You are a helpful assistant.`; // Enclose input variables in double curly braces. const character = "two brothers"; const location = "space"; const dynamicPrompt = hpf`Write a story about ${{ character }} set in ${{ location, }}`; -
Send request to Helicone
All incoming requests will show up in your
Requestspage.Make sure to have both valid OpenAI and Helicone API keys.
-
Experiment and evaluate prompts
Once you've set up prompts in Helicone, you can:
- Run experiments
- Evaluate the output
- Improve your prompt setup (since you've already set it up)
If you use any other provider, you can use Helicone too. Please refer to Helicone's documentation for most up-to-date instructions.
2. OpenAI Eval: Standardized Evaluation Framework
Pricing: Freemium, open-source

What is OpenAI Eval?
OpenAI Eval is an open-source framework for evaluating and testing LLM applications, built by OpenAI. It provides tools for dataset-driven testing, prompt-response evaluations, and benchmarking model performance.
Key Features
- Evaluation-Focused Framework: Provides tools for dataset-driven testing, prompt-response evaluations, and benchmarking model performance.
- Custom & Templated Evaluations: Supports the creation of bespoke assessments tailored to specific application needs.
- Model-Graded Evaluations: Supports evaluations where models assess their own outputs or those of other models, enabling self-referential testing.
Differentiators
- Integrated with OpenAI's ecosystem, logging/evaluating OpenAI outputs is easy.
- Handles diverse evaluation types, from basic Q&A to complex, multi-step workflows.
- Offers templates (basic and model-graded eval) that can be used out of the box.
Bottom Line
OpenAI Evals' is focused on rigorous testing and benchmarking, while other tools offer more comprehensive features like prompt management and production-monitoring. OpenAI Evals is restricted to teams using OpenAI APIs only.
Please refer to the official evals docs and cookbook for most up-to-date instructions.
3. Promptfoo: CLI for Systematic Evaluation
Pricing: Freemium, open-source

What is Promptfoo?
Promptfoo is an open-source CLI and library for systematic evaluation, testing, and optimization of prompts in LLM applications.
Key Features
- Batch Testing: Streamlines comparison of prompts against predefined scenarios.
- Test-Driven Development: Encourages structured prompt testing, reducing reliance on ad hoc experimentation.
- Integration Flexibility: Compatible with major LLM providers and open-source models.
- Evaluation Metrics: Offers customizable metrics for nuanced LLM output assessments.
Differentiators
- Promptfoo can be used as a CLI, library, or integrated into CI/CD pipeline.
- Built-in red-teaming and security testing capabilities.
- Open-source and customizable for specific workflows.
Bottom Line
Promptfoo is designed to run locally, which means users have more control over their data. However, running evaluation require intensive time and compute resources. Promptfoo might be less suitable for smaller teams.
For detailed setup instruction, refer to Promptfoo's documentation.
4. Comet Opik: Observability and Eval Platform
Pricing: Freemium, open-source

What is Comet Opik?
Opik is an open-source platform designed for evaluating, testing, and monitoring LLM applications. It integrates seamlessly with tools like OpenAI, LangChain, and LlamaIndex, providing end-to-end observability during development and production.
Key Features
- Tracing & Logging: Records all LLM calls and traces, and enables debugging and optimization by providing detailed step-by-step insights.
- Evaluation Metrics: Supports pre-configured and custom evaluation metrics. Handles advanced assessments like hallucination detection and factuality.
- CI/CD Integration: Integrates into CI/CD pipelines for performance baselines. Enables automated testing of LLM pipelines during deployment.
- Production Monitoring: Logs real-time production traces to identify runtime issues. Analyzes model behavior on new data and creates datasets for iterative improvement.
Differentiators
- Built-in support for popular platforms (OpenAI, LangChain, LlamaIndex).
- Covers evaluation, debugging, monitoring, and testing in one unified platform.
- Open-source and customizable to fit diverse workflows and scalable for enterprise needs.
Bottom Line
Comet Opik is designed to handle millions of traces, making it suitable for production monitoring in addition to LLM testing.
For detailed setup instruction, refer to Opik's documentation.
5. PromptLayer: Observability and Eval Platform
Pricing: Freemium, not open-source
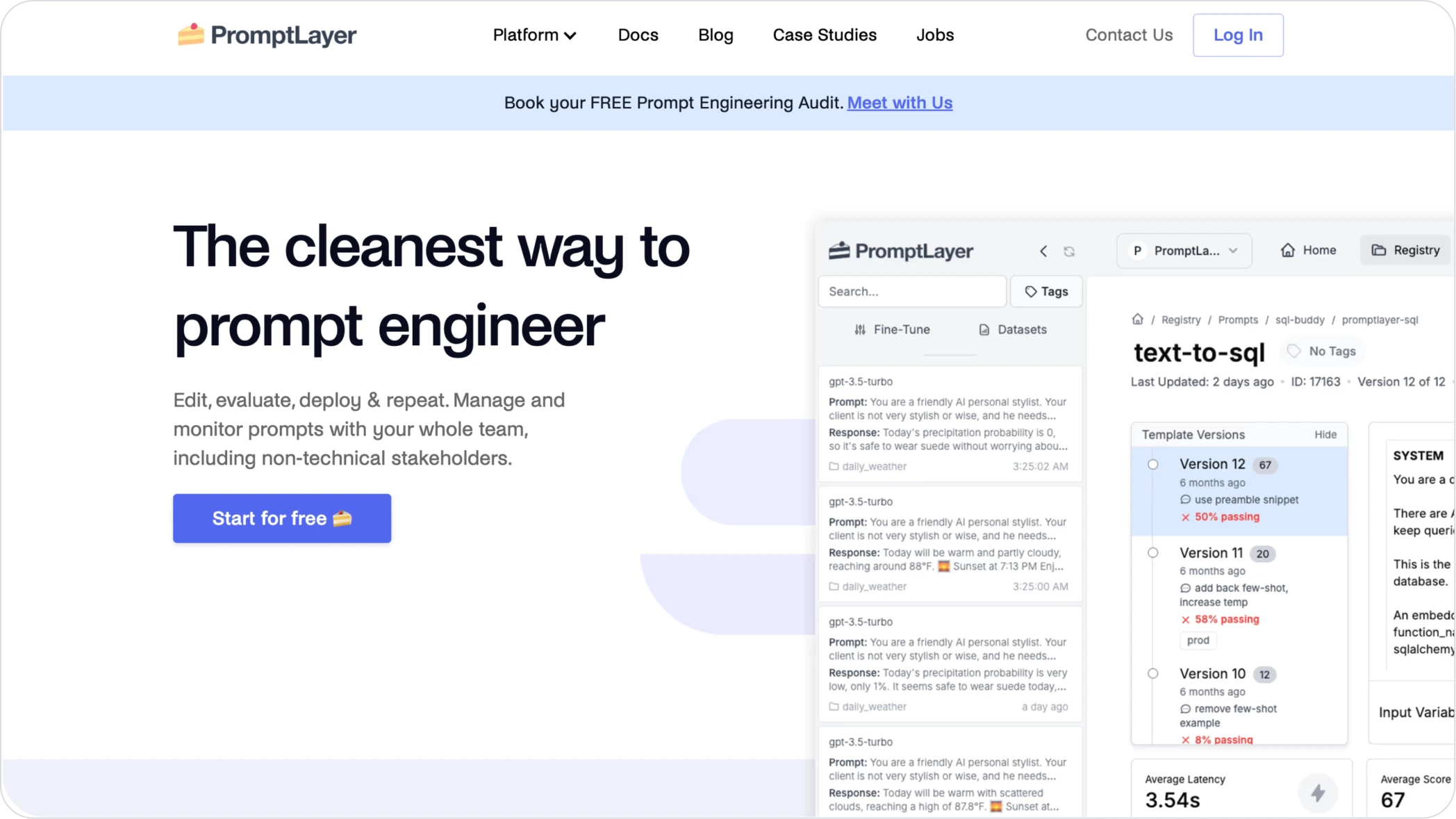
What is PromptLayer?
PromptLayer is a platform that enhances prompt engineering by providing tools for the management, evaluation, and observability of LLM interactions.
Key Features
- Prompt Management in the UI: Both technical and non-technical members can collaborate on creating, editing, and deploying prompts.
- Observability & Analytics: Logs inputs, outputs, costs, and latencies, providing insights for performance optimization.
- Evaluation Toolkit: Supports historical backtesting, regression testing, and model comparisons.
- Proxy: Acts as middleware for API providers, seamlessly integrating into development workflows to capture request/response in real time.
Differentiators
- Allows non-technical stakeholders (i.e. product managers, content experts) to assist in prompt engineering.
- CMS-like prompt features like structured version control and deployment.
- Combines logging, observability with evaluation to improve prompt performance.
Bottom Line
PromptLayer is a good comprehensive tool for overall performance improvement. However, it can be expensive for high-volume usage and has a learning curve for more complex features.
For detailed instructions, refer to PromptLayer's Programmatic Evals doc.
6. Traceloop: Real-Time Observability Platform
Pricing: Freemium, open-source
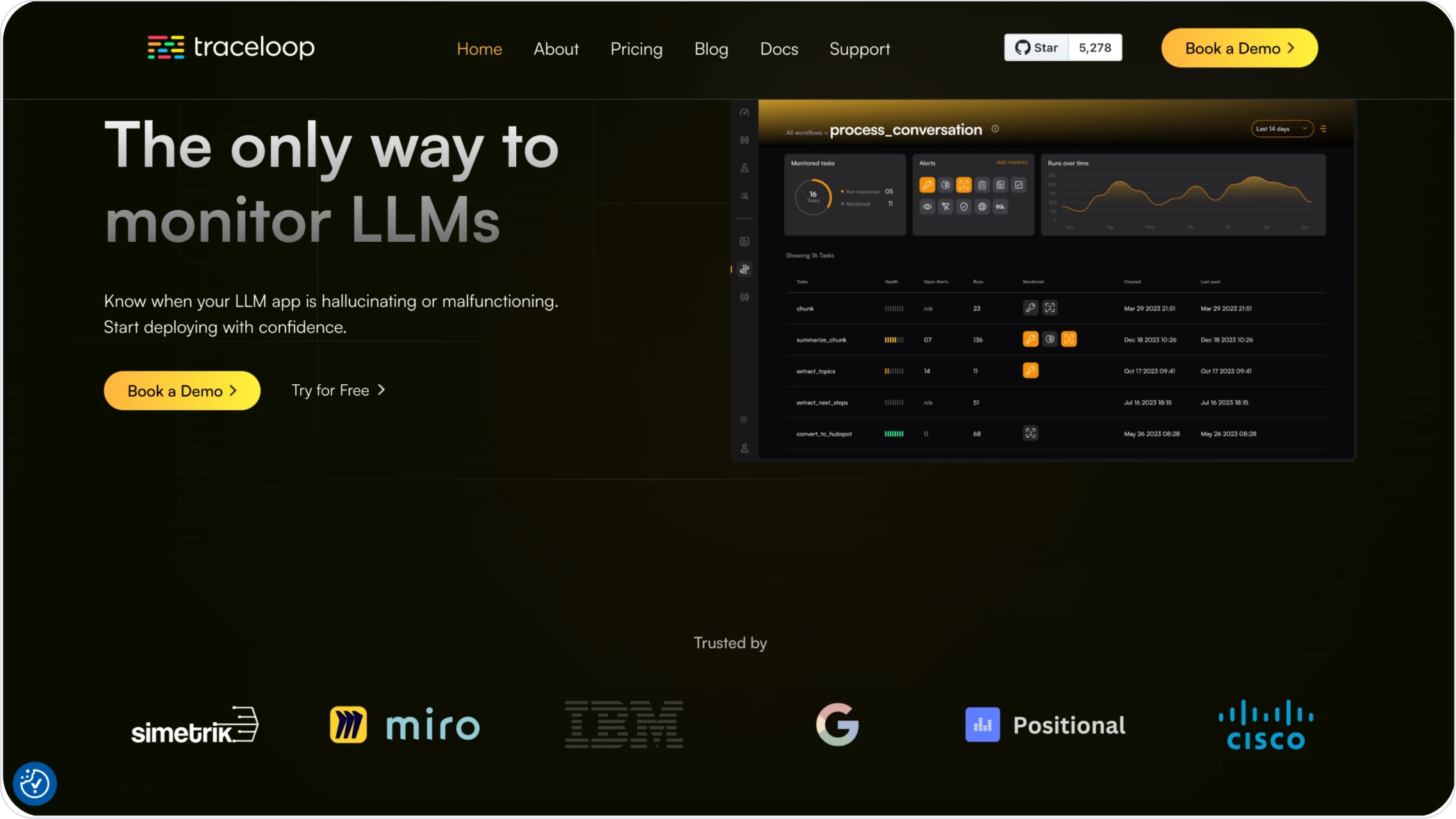

What is Traceloop?
Traceloop is an open-source extension of OpenTelemetry, offering real-time monitoring and debugging to maintain consistent output quality. It integrates well with existing observability tools and AI frameworks.
Key Features
- Real-Time Alerts: Notifies developers of unexpected output quality changes, enabling quick issue resolution.
- Broad Compatibility: Supports a wide range of LLM providers and vector databases, ensuring extensive monitoring capabilities.
- Automatic regression detection: Correlates metrics with system changes to automatically detect regressions.
Differentiators
- Detects issues like hallucinations without relying on additional LLMs.
- Can be integrated with CI/CD pipelines.
Bottom Line
Traceloop has comprehensive monitoring, and its hallucination detection also shows promise. However, like many alternatives in the market, its effectiveness is still an evolving area of development.
Refer to Traceloop's demo repo or prompt docs for setup details.
7. Braintrust: End-to-End LLM Platform
Pricing: Freemium, not open-source
What is Braintrust?
Braintrust is an end-to-end platform that streamlines LLM development by enabling prompt creation, testing, deployment, and performance tracking in a single workflow.
Key Features
- Real-Time Monitoring: Logs LLM traces and provides insights into app performance.
- Iterative Prompt Workflows: Diagnoses regressions and optimizes performance.
- Custom Scoring Mechanism: Define scoring criteria in natural language or code, allowing precise evaluation of LLM outputs against expected results.
- Dataset Management: Capture and organize rated example datasets, allowing the creation of scalable and secure "golden" datasets for training AI models.
Differentiators
- Developers can compare experiments to previous ones without requiring pre-existing benchmarks.
- Ability to evaluate performance across different models and parameters for optimization.
Bottom Line
Braintrust primarily focuses on advanced evaluations and CI/CD integration. For teams looking for an eval-specific solution, Braintrust can be a good choice.
For setup information, please refer to Braintrust's Eval SDK documentation.
Choosing the Right Prompt Evaluation Framework
The best prompt evaluation framework varies depending on your needs. Here are a few things you should consider:
-
Core features: Decide if you need a tool specialized for prompt evaluation. If you are looking for an end-to-end observability platform, Helicone and Comet are good options. If you are looking for an eval specific solution, Braintrust is a good choice.
-
Integration: Make sure the framework of choice is compatible with your existing stack. For example, OpenAI Evals is limited to OpenAI APIs, while platforms like Helicone and Promptfoo supports multiple LLM providers including OpenAI, Anthropic, Azure, Google, as well as open-source models like Llama.
-
Scalability: For production-scale evaluations, choose a tool that can handle large datasets and high-volume prompt evaluations efficiently.
-
Team-size: For teams needing fast integrations and ease of use, Helicone and Promptfoo have lower overhead and the simplest integration.
-
Metrics Support: Verify that the framework allows you to run the evaluation of choice. Some platforms only support LLM-as-a-judge, while others allow you to define custom evaluators.
-
Usability: If you are looking for a solution for your team with mixed technical experience, consider choosing a platform with intuitive UI and detailed documentation.
Bottom Line
As LLMs become increasingly central to modern applications, prompt evaluation frameworks have evolved from simple testing tools into comprehensive platforms for managing, monitoring, and optimizing AI interactions.
Whether you choose an open-source solution like Helicone or a commercial platform like Braintrust, these frameworks are essential for building reliable, production-grade LLM applications that consistently deliver value to end users.
Further Reading
-
How to Test Your Prompts with Helicone
-
Golden Datasets vs. Random Sampling Explained
-
Prompt Engineering Techniques & Best Practices
Questions or feedback?
Are the information out of date? Please raise an issue or contact us, we'd love to hear from you!